How can I define nonlinear trajectories in a growth curve model?
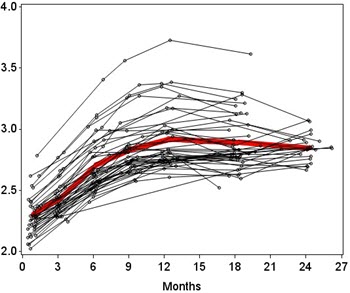 Growth curve models, whether estimated as a multilevel model (MLM) or a structural equation model (SEM), have become widely used in many areas of behavioral, health, and education sciences. The most common type of growth model defines a linear trajectory in which the time scores defining the slopes increment evenly for equally spaced repeated measures (e.g., values representing time are set to 0, 1, 2, 3, etc.). These values can be modified to allow for unequally spaced time assessments or to place the zero value at the beginning, middle, or end of the series, but the slope of the line always implies an equal change in the outcome per-unit change in time.
Growth curve models, whether estimated as a multilevel model (MLM) or a structural equation model (SEM), have become widely used in many areas of behavioral, health, and education sciences. The most common type of growth model defines a linear trajectory in which the time scores defining the slopes increment evenly for equally spaced repeated measures (e.g., values representing time are set to 0, 1, 2, 3, etc.). These values can be modified to allow for unequally spaced time assessments or to place the zero value at the beginning, middle, or end of the series, but the slope of the line always implies an equal change in the outcome per-unit change in time.
However, many constructs we study do not change linearly over time. Instead of equal change per-unit time, there is often differential change with respect to time. So there might be greater change earlier in time that then systematically slows (e.g., reading ability in young children), or the rate of change might increase positively but accelerate with the passage of time (e.g., substance use in adolescence), or the construct might slowly increase, peak, and then slowly decrease (e.g., heavy drinking in young adults). Regardless of particular form, it is critical that an appropriate nonlinear function be incorporated into the growth model to protect against making biased inferences about the nature of change over time. Fortunately, there are many options available to capture nonlinear change over time in growth models.
A classic option is to transform either time or the repeated measures and then fit a usual linear growth model (e.g., compute the natural log of time). Although a useful approach, often the nonlinear trajectory is of substantive interest and we don’t want to transform it to a linear form. An alternative is to estimate nonlinear trajectories in the form of polynomial functions. These are quite easy to implement and simply involve adding higher-order powers of time to the model. For example, a linear model might numerically code time as 0, 1, 2, 3; a quadratic model would add to this 0, 1, 9, 16; a cubic model with in turn add a cubed component of time. This approach can be quite useful in practice, but often become increasingly complex to interpret in a substantively meaningful way. For example, just like a linear trajectory, polynomials are not bounded and thus tend toward infinity. This might thus serve as a useful approximation to the observed data, but any polynomial will eventually turn toward positive or negative infinity (making it less use for modeling, say, reading achievement).
Polynomials pre-define specific functional forms through the choice of time coding. One alternative that is available within the SEM growth model is to freely estimate a subset of loadings on the slope factor (sometimes called a basis function). Thus, whereas a line would be defined by fixing factor loadings (e.g., 0, 1, 2, 3, 4), alternatively the first two might be fixed to 0 and 1 and the rest freely estimated (e.g., 0, 1, 2.5, 4.2, 6.1), reflecting differential change over time (in this case, accelerating). The advantage of this method is that it provides a very flexible way to obtain data-informed nonlinear trajectories, but the disadvantage it that it no longer corresponds to a pre-defined growth function (e.g., a quadratic trajectory). This in turn can often make substantive interpretation difficult.
An option that we have found very useful in our own work is called a piecewise growth model. Instead of defining a single trajectory to span the entire window of time under study, a series of linear trajectories are estimated that approximate different parts of a nonlinear trajectory but are connected using “knots” at specific inflection points. So if there is a complex nonlinear trajectory that increases, slows, peaks, decreases, and plateaus, three linear trajectories can be simultaneously estimated to approximate the initial increase, the subsequent decrease, and the final asymptote with each line tied to the next at the inflection point (where the curve turns). Although only an approximation, each linear piece can be unambiguously interpreted in the usual way (e.g., linear change in the outcome per unit change in time).
Finally, there are a set of more complex models are not just nonlinear with respect to time (as the prior approaches all are) but are nonlinear in the parameters. Examples include a broad class of nonlinear functions such as exponential growth and decay functions that do not tend toward infinity and instead have asymptotes defined as a natural part of the trajectory. These models provide for the estimation of nonlinear functions with parameters that are nicely interpretable from a theoretical perspective, but they also require more complex nonlinear methods of estimation, the selection of which should be made with care.
Below are several recommended readings, and we also address these topics further in an Office Hours video on our YouTube channel.
Biesanz, J.C., Deeb-Sossa, N., Aubrecht, A.M., Bollen, K.A., & Curran, P.J. (2004). The role of coding time in estimating and interpreting growth curve models. Psychological Methods, 9, 30-52.
Cudeck, R., & Harring, J.R. (2007). Analysis of nonlinear patterns of change with random coefficient models. Annual Review of Psychology, 58, 615-637.
Flora, D. B. (2008). Specifying piecewise latent trajectory models for longitudinal data. Structural Equation Modeling, 15, 513-533
Grimm, K. J., Ram, N., & Hamagami, F. (2011). Nonlinear growth curves in developmental research. Child Development, 82, 1357-1371.